






Cloud Cost Management
To begin with, managing your cloud costs has been a thing since people have been using cloud computing. For well over a decade, people have been shifting their infrastructure to the cloud and very rapidly discovering that their credit card hits its limits without too much thought. In fact, that's precisely the point - moving your infrastructure to the cloud without a lot of thought is a sure-fire recipe for disaster. Over the intervening years, it has created a cottage industry of its own around cloud cost management. One favourite blog I follow is from Corey Quinn of the Duckbill group (we are not affiliated with them in any way), who regularly documents the amusing failures of companies at managing their cloud costs.
Since the early days, AWS (and presumably all of the other cloud platforms as well) has provided numerous mechanisms for managing these costs, and over the last few years the offerings in this area have grown. I'll try to present a brief but not comprehensive look into some of these, but the problem remains - the number of products has dramatically outpaced the number of cost saving options available. Alternatively, the cost saving mechanisms may exist, but it is getting harder and harder to understand how to apply them to the full suite of products you might use.
Let's take a look at a particular situation we've recently been through which gives an example of where it's not so straightforward.
EC2 costs... and?
We've recently jettisoned a significant portion of a legacy CI environment that was running on EC2 instances in one of our accounts. Managing our own build agents is not a core part of our business and has long been something we've wanted to avoid, so shifting those workloads elsewhere was something we've wanted to do for a while. When it comes to EC2 costs you have the richest set of options available to you:
EC2 Reserved Instances
These are in many ways the most straightforward, but also the most limiting. You can purchase Reserved Instances within a given family up to 3 years, fully paid up-front for maximum savings. But who has that amount of certainty? New instance families and types are being released every year, and many companies are migrating from X86 to ARM architecture, not to mention having dynamic and changing needs from year to year. So this can also lock you into a situation you cannot easily escape.
There are options, of course - you can try your luck with an AWS Support ticket but that may not lead anywhere. The point of locking in the pricing also means you have made that commitment - unless there are sufficient mitigating circumstances. For example, if you just purchased the RIs but selected a particular option in error. Your odds of getting a refund half-way into a 3-year commit are fairly low though.
Another option is the AWS Reserved Instance Marketplace, where you can resell RIs to other interested buyers (usually at a discount). You'll make a loss, but perhaps not a complete write-off. There are conditions surrounding this option though, so make sure you understand what requirements this places on you before committing to something large. Alternatively, there is yet another cottage industry around services that provide some of the cost savings of RIs but with the flexibility of Savings Plans. These companies will purchase the RIs on your behalf and allow you to use them, while taking them back (presumably spreading them to their other customers) when they are no longer needed - and take a cut of the savings in the process.
Savings Plans
Savings Plans have a lot of flexibility while not having the savings potential of Reserved Instances. You commit to a certain amount of hourly spend, a term length, and how much to pay up front, and you get a corresponding saving on that commitment. If you don't use it, you still pay it. If you spend over that amount, the overage is charged at regular on-demand rates.
What is also nice is that you can pick the target of EC2 instances, Sagemaker, or just a blanket commitment over "compute" (that covers EC2, Fargate and Lambda). This is an ideal case if you know you will be using computational resources but don't know how many instances, instance family, instance type etc. Sagemaker coverage is another nice benefit (although we'd love to see Glue added!).
On-Demand vs Spot
Spot instances have long been a popular option to make use of AWS's excess capacity at often dramatically reduced pricing - up to 90% reportedly. Since AWS retired the bidding model around 2018, it has also become a lot easier to use Spot instances, and again this has led to a cottage industry around usage of Spot instances when you don't want to do the dirty work yourself. Some tools such as Autospotting have also emerged to ease the use and maximise the savings possible.
The main disadvantage is that your instances might be "pre-empted" (taken away before your workload expects it) - this makes it mostly ideal for resumable workloads, or workloads that can tolerate interruption with less than two minutes' warning. While we considered it for our CI fleet, there were some jobs that did not tolerate interruption very gracefully and we had to learn that the hard way.
Exploring the costs
Compute costs can certainly dominate the monthly bill, but before assuming this you really need to take a look at the Cost Explorer. Like many other AWS features, it has only improved with time and today provides a very comprehensive overview of your costs by multiple dimensions and timeframes.
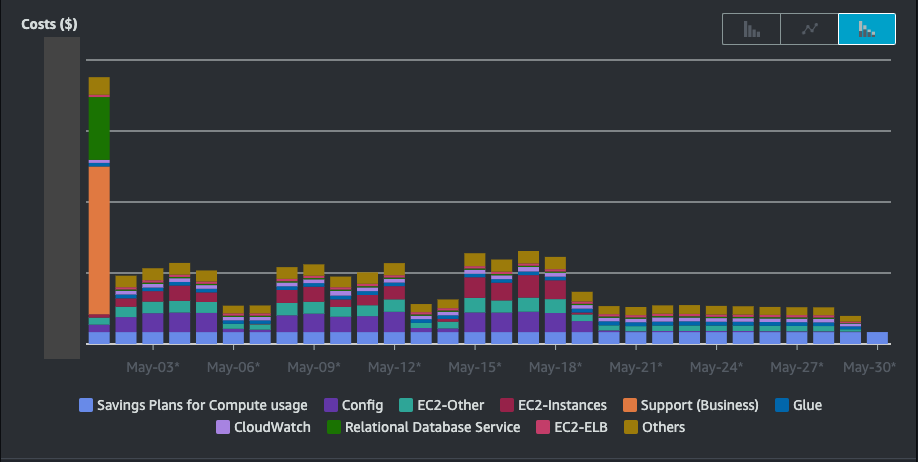
In the above image you can clearly see where things changed for the better, in terms of our daily spend. Two of the colours in the bars seem obvious and self-explanatory - we have a fair amount of EC2 Instance and also Savings Plan for Compute costs. Now we've dipped our toe into the costs pool, let's start dissecting these categories.
On-Demand spend AND Savings Plan?
So what is going on here? One reasonable explanation is that I haven't calculated our usage accurately enough and have not got enough coverage of our compute usage in the Savings Plans. In practice, a fleet of CI agents scale up dramatically during the week, and then largely sit idle (i.e., zero instances) during the weekend. You can pick a matching value for your weekday usage commitment, but that will then go unused during the weekend and ruin your weekday savings. Or vice versa, underutilising the Savings Plan in order to avoid spend on weekends leaves you with more On-Demand spend during the week.
There is probably a mathematically ideal point where you have perfectly balanced the two, but unless your spend in this category is in the five-figure range per month, it may not be worth spending a lot of time on (or pursuing other more achievable savings elsewhere). It is always worth keeping in mind how much your own time as an individual contributor is worth, and whether the potential savings will pay off in the near future.
One other critical thing to pay attention to here is dramatic changes - as in our case - that might occur in your compute spend and the lifetime of your Savings Plans. Our Savings Plan expiry is coinciding roughly with our shift in usage, so there will be relatively little economic penalty. You don't want to be shifting a large part of your compute spend elsewhere and still paying for it half a year later.
NAT Gateway traffic
This is a perennial favourite (for the wrong reasons) of cloud cost management gurus, since it is hard to do away with the humble NAT gateway. Providing your cloud resources are in a private subnet, you'll need either several NAT gateways (for redundancy) or NAT instances (which were originally a recommendation from AWS but have long since fallen out of favour) and will pay for the privilege. More recently, some alternative solutions such as fck-nat have popped up to deal with the cost of running NAT gateways.
At $0.045/hour and $0.045/GB of traffic, especially for CI fleets that tend to download both a lot of code and dependencies from the internet, you may find that your bill in this category is uncomfortably high. They fall into a category of costs that seem punitive for the wrong reasons - you want the security of having your resources in private subnets, you want appropriate redundancy across availability zones, and you want to segment your network appropriately for security. If you do all of these things, however, you may find that you now have a fleet of literally dozens of NAT gateways - just in a single VPC! In our case it was a category easily crossing the $1000/month threshold for more investigation.
One explored alternative is just dropping your instances into a public subnet - you can achieve security with security groups and more recently AWS Network Firewall rather than relying on the NAT Gateway to separate your resources from the world (although this doesn't apply to all resource types). This means that there is no NAT Gateway charge for either the gateways themselves or the traffic into them (or EC2 instances). Unfortunately for us, some workloads depended on the persistent IPs associated with the NAT Gateways, which stopped working when using EC2 instances in public subnets, so that was a non-starter. It's worth checking to see if that would work for you, though, as this cost category can add up quickly.
EBS usage
Unless you are using some of the more specialized Instance Store-based instance types (e.g. m5dn.large) then you'll have EBS storage attached to your instances. This is sadly not free, and pricing scales up by the GB (and IO capacity, in the case of GP3) volumes. Once GP3 volumes were available, we jumped on them to enjoy the slightly reduced pricing with virtually no downside. As mentioned, the CI fleet is typically scaling to hundreds of nodes during a given workday and without thinking too much about it, you might miss the EBS storage component.
For example, if we have 200 instances all with 100GB of GP3 storage running for a typical 8 hour workday, at $0.08/GiB-month this ends up as around $18/day. Of course, if your workforce is spread across multiple continents you might find that your CI fleet runs a lot longer than an 8 hour workday. This just crosses the $500/month mark which I typically use as a guide for when to start seriously looking at costs in order to understand if it is truly necessary. In the case of a CI fleet, it can be educational to understand whether all that space is required, or whether the relatively short lifetime of the individual instances means that they never really fill up.
Of course, it's usually not worth saving a few dollars if it will dramatically impact developer productivity negatively, so keep that in mind.
Sidebar: Playing the Sliding Puzzle with EC2 costs
You've probably played a Sliding Puzzle before - it has (usually) space for 16 tiles, one of them is removed and you have to get the tiles into order or recreate a picture. You can't move one tile without moving another one first, sometimes making progress and sometimes going backwards. It can feel a lot like that when trying to shift costs around in a cloud provider.
Now that I've described some of the components of cost around EC2 it's worth mentioning some of the initial attempts to improve the costs, that ultimately didn't work out so well. When I first encountered the CI fleet, there were some problems with the autoscaling logic and often the fleet would sit at maximum capacity for the entire week - far from ideal. Initially I made two changes - fixing the scaling logic so it more aggressively scaled down the fleet and also introduced spot instances with a diverse set of instance families to ensure we didn't run out of instances in one AZ.
Unfortunately this had some undesirable side-effects. The lifetime of any given instance dropped, partially because we were scaling down more aggressively and also because the autoscaler has no awareness of whether an instance is busy when it is terminated. The default ASG behaviour is to terminate the oldest instance in the group, without any understanding of whether it is ready to be terminated. The instance could be in the middle of a build job, which has a negative impact on developer productivity as the overall build pipeline will now take longer (after retrying the interrupted step).
Another problem was that with shorter lifetime, fewer containers and dependencies were cached on CI hosts. Each time an instance came back up, it would need to refetch a lot of resources from both within our VPC and the internet - this led to an explosion in our NAT Gateway traffic, effectively nullifying the EC2 cost savings in the process - even while using Spot Instances. We could fix the unexpected job termination problem by having the CI hosts self-terminate (only terminating themselves when they had been idle for a certain amount of time), but could not do very much about the overall churn in instances brought on by more aggressively scaling up and down in response to demand, leading to further problems with AWS Config as detailed in the next section.
One attempt to fix the NAT Gateway traffic problems was limiting our Git clone/fetch depth to only the most recent commit. This reduced the clone traffic from several gigabytes for our largest repositories to less than 100MB, which was contributing terabytes per month to our incoming traffic bill. This has the side-effect of not fetching all of the tags and also non-default branches. Due to some logic in our build pipelines we depended on seeing all of the branches and tags in the repository, which caused some other issues with the build process. At the end of all of this it really seemed like it was near impossible to make cost savings while not impacting developer productivity in some way.
Ultimately we found an acceptable fetch depth for Git operations, made some changes to build scripts, and set reasonable idle timers for CI hosts to avoid the biggest effects of churn, but this led to another interesting discovery...
Config
I saved the best one for last - this one was a bit of a surprise once we stumbled upon it in the monthly cost breakdown. Especially if your business is Compliance-minded, you'll likely have AWS Config enabled in order to record the history and changes of resources in your account. You can also enable specific Conformance Packs such as FedRAMP or CIS Benchmarks in order to understand your compliance posture and which resources are not in compliance.
Unfortunately, each one of these packs contains numerous rules, and these often evaluate the same resources multiple times from different angles. For example, is the EBS volume of a given EC2 instance encrypted? Does that EC2 instance have only IMDSv2 metadata enabled? Each one of these rules executes across all live resources in your account, and will continue to monitor them after they have been retired in some cases. If you have a lot of churn in your resources, you may find that there is a fairly high rate of rule evaluations - and unfortunately, you pay for each one.
When tallying up the costs in this category we sadly came to the conclusion that it added up to literally thousands of dollars of spend. It can in fact exceed the cost of the very resources it is responsible for monitoring. That leaves us with a fairly difficult decision - do we abandon monitoring compliance of these CI fleet instances entirely, or is there some middle ground? Unfortunately AWS Config is enabled across an AWS Organization, and will monitor all accounts under that Organization. It would be possible to segregate the CI workloads into their own account, and potentially exclude that account from Config monitoring, but would you really want to? CI workloads are some of the most sensitive and in need of scrutiny, with the proliferation of supply-chain attacks, so it seems like this is one area most in need of monitoring and reporting.
This leaves most companies in a tricky spot. The only apparent solutions are to use external cloud-managed services (e.g. Github Actions hosted runners, Gitlab CI or Azure DevOps), or devise a way of limiting the resource churn. One example of this would be to only use far larger instances, and bin-pack containerised CI workloads onto fewer EC2 instances that have longer lifetimes. Combined with Spot Instances and Savings Plans, this could be a workable solution. Combining the spiky workloads with other more stable workloads in one containerised environment might be another, depending on your risk appetite.
Conclusion
When faced with an ever-increasing cloud bill with dozens of cost categories it can be a challenge to pick apart exactly what is driving the increase the most. Sometimes it can be surprising and eye-opening. I'd recommend at least spending a day or two drilling down into the Cost Explorer to gain an understanding of your current spend and what drives it - at the very least you'll be able to spot unusual patterns when they occur in future, and with any luck, determine opportunities for reductions that don't materially impact how you do software development.
In our case, it formed the conclusion that our total spend on self-managed CI was several times greater than the cost we were paying to the CI provider itself, and that non-EC2 Instance costs far outweighed the compute costs alone. This level of understanding is valuable when your spend is small - it's essential as it continues to grow in the future.